This post goes over some of our methodology & rationale when we created this year’s (2024) Northeast Collegiate Cyber Defense League competition environment.
Topics that I’m planning to cover
I also have another post going through the CTF challenges we released
Deployment Methodology
Most of our deployment methodology was carried over from last year but just made more advanced.
Our deployment process goes as follows:
- Write out our baseline image with Ansible
- Build out base images with Packer
- Deploy all infrastructure automatically using Terraform
- Run post-deployment Ansible against each team
Our goal which we accomplished was to have everything as code, not just IaC but also configuration. Additionally, code in the repository should be able to be used by other black teams (our region or others).
I’m personally planning to create a cross-region directory of services/code. This ideally will allow quicker creation of environments in the future without having to write playbooks from scratch.
Infrastructure
Code to create your own competition can be found here on GitHub.
Like last year it was decided pretty early that we would be fully* on AWS again this year.
WireGuard
Connectivity to infrastructure was done through the user of WireGuard. We adopted the same tools that were used last year wg-easy.
I created an Ansible playbook to fully deploy the VPN. Installs dependencies (docker), for each team, creates a wg-easy container, and then creates the team’s clients.
The code used to create is can also be founder on GitHub. Fair warning the code is very janky, it makes HTTP requests against the container’s web UI to authenticate and create clients.
For regionals, we intended to have clients connect over a full tunnel to “bypass” Paces Universities network (Using 0.0.0.0/0 also raised more issues). The issue with that is Wireguard does not have ways to restrict access on the server (on the client there are AllowedIPs but thats superficial). The solution is to have each wg-easy container on its own docker network, then on the host, we can use iptables to restrict which internal network can communicate.
Qualifiers
This is our internal network diagram for qualifiers a little nicer than what we give out in the packet. One of my finest pieces of art 😉
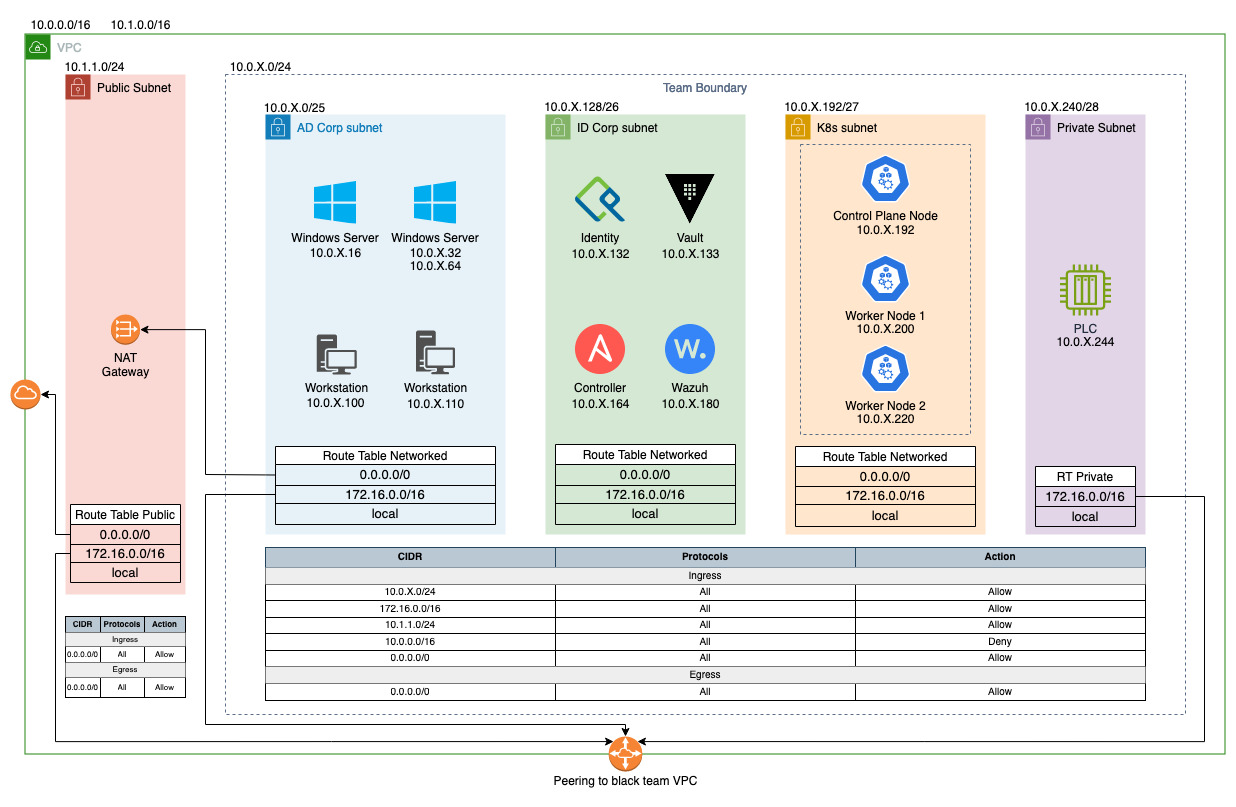
Networking
Last year (2023) for qualifier we used a transit gateway to connect each team back to the black team VPC.
This year slightly due to the cost we went to using VPC peering which works great. Except that NAT cannot go over it, this sucks because if we want each team to have its own VPC it would require 20 NAT Gateways each with a public IP. 💸
The solution; have one giant VPC that the team can share! By default, teams could communicate with each other, but with Network Access Control Lists (NACLs) on each team’s subnets, this prevents communication to subnets other than public (NAT) & black team (VPN, scoring, and red team).
Kubernetes
Everyone’s favorite technology this year!
The actual install for qualifiers was pretty stock; version 1.28 with containerd. For external ingress, we used the ingress controller haproxy-ingress and for pod networking, we used flannel (simple but does not support network policies (shout out to the team that mentioned that)).
Hosting the PostgreSQL database on Kubernetes was fun, I think database security/management was new for most teams. This bites teams during regionals…
Setting up GitLab was a pain because it needed to be fine-tuned for memory requirements (nodes had 4G) and we did not introduce any volume replication in the qualifiers. Our end Ansible helm task is ~100 lines configuring nested helm charts.
A recurring thing during qualifiers was teams trying to SSH into the Kubernetes nodes over port 22, this would not work since that port is used by GitLab for git.
Semaphore
I don’t know why we originally picked Semaphore but we had issues with getting Ansible to run on it, would just hang until it was canceled. We believe it was an issue with the database BoldDB (EOL 2017). That’s why we did not have any major injects around it in qualifiers and outright 🪓ed it in regionals.
Windows
I don’t touch Windows but I am responsible for giving the CA servers 2 IPs 😅
Regionals
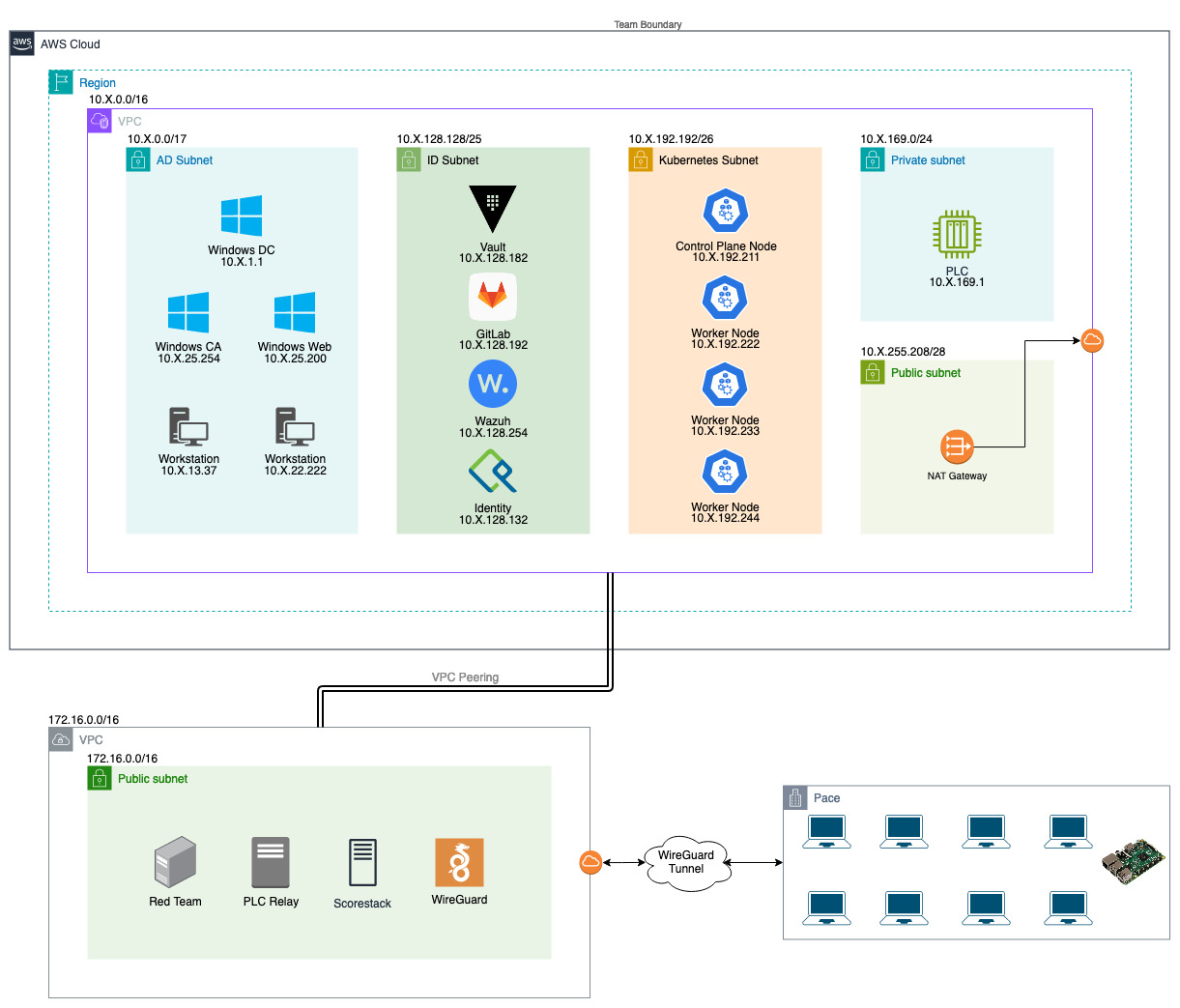
AWS
For regionals teams were given access to the Amazon Web Services console, what could go wrong? 😱
Actually, not much. We implemented Service Control Policies on all of the team AWS accounts. They prevented teams from performing actions that were not in scope, using different regions, or deleting black team access.
With services that were available to teams, we chose to only focus on cloud agnostic ideas; virtual machines (EC2), networking (VPC) & identity management (IAM). Additionally, we made available CloudTrail for audit logs, S3 so they can be ingested by Wazuh, and access analyzer (I don’t think any teams used it tho).
A few teams got caught up with the default permissions they were assigned. The users had full read access and then only iam:*. Privesc 101 😂
GitLab
Replacing the Semaphore instance we had a dedicated box for GitLab. Unlike during qualifiers, we did not have it use the K8s PostgreSQL high availability database.
Kubernetes
Kubernetes for regionals was fun! I used setting up the environment as training for the Certified Kubernetes Security Specialist exam. 😁
I’m not going to go into all the misconfigurations/vulnerabilities there, keeping them for next year. But everything was fixable without needing to reinstall the cluster.
For starters, we added one more worker node bringing it up to three workers & one control plane node. All nodes ran containerd but on two of them, they had docker as the cri which made things funky and probably insecure (2375).
For some CI/CD (CD in this case) we introduced ArgoCD a tool I love for GitOps. It helped with deploying services for the black team (Falco, Longhorn, NextCloud, etc.) decreasing the deploy time of the infrastructure.
Ahh the shop, my child. This was a scored service that started as failed and only one team got it green… It was as simple as creating a release on the GitLab repository, this would trigger the image build (using the runner) and then would be picked up by the container and deployed. The final step would be setting up TLS (the check said HTTPS) and the configuration could be copied from any other ingress.
A new tool for me was Longhorn which is a cool storage solution used for managing volumes.
Falco is a tool I snuck in for blue teams. It hooks into the node’s system calls (ebpf or kernel modules) and alerts on suspicious/malicious activity. If you want to learn more I recommend this book from O’Reilly.
Scoring
Nothing new to this year but scorestack is never fun to work with. (How we lose black team leads)
We may start our own scoring system that does not require an ELK stack, more scalable, and supports other score types.
Injects
I authored a few of the injects this year, to the blue teams dismay (probably).
Qualifiers
Removal of Unauthorized Web Servers
This was a fun and easy inject (at least I thought it was going to be). It tasks the teams to look for “unauthorized web servers… …an image hosted on public.ecr.aws, specifically based on the nginx” and then remove them. Knowing that we have Kubernetes running in our environment that’s probably a good place to look first. Two can be found pretty easily kubectl get pods -A -o yaml | grep public.ecr.aws finding the last (third) requires a little more threat hunting. Looking at what’s running directly on the nodes (containerd) with a tool like nerdctl or crictl we can find a container using the public.ecr.aws registry.
Database Redundancy
This is a harder one but still doable, it just tasked teams with making the database redundant. With the helm bitnami/postgresql-ha it’s simple; create a new persistent volume (already used for the primary db) then update the helm chart by setting postgresql.replicaCount=2. To verify port forward the first pod add some data & verify on the second.
Regionals
Centralized Kubernetes Audit Logs
Different than a previous inject which was looking for instances to be hooked up to Wazuh, this is looking for Kubernetes API audit logs. Luckily there is a guide by Wazuh for setting this up Auditing Kubernetes with Wazuh, following it pretty much line for line (changing IPs) we can get it working. We don’t even need to change the policy to log secrets since it captures everything at the metadata level excluding the RequestReceived stage. The only change from the Wazuh blog post is to change the Python path in the systemd service.
Securing Kubernetes Application
Fixing and deploying an application is a scenario not uncommon for a DevSecOps engineer.
Starting by getting the low-hanging vulnerabilities (free online tools to do this KICS) out of the manifest, setting privileged to false, removing the NET_ADMIN capabilities, and 100Gi of memory that’s probably supposed to be 100Mi.
In the manifest, there is a link to the public image registry for the app. From it, we can see that the latest tag is the same as the v1.3 specifying that the sha256 of the image would also grant more points.
Advanced techniques would have been to run it as non-root. This would require the image switched to v2.0 (A tool like dive can easily show build steps).
There are additional deployment security techniques that I’ll quickly list:
- seccomp profiles
- non-root
- read-only filesystem
- dropping all capabilities
- resource limits
Event securing the deployment environment would grant additional points
- Removing overly permissions service account
- Network Policies
- TLS on ingress
Deploying the deployment is also easy points (kubectl apply -f deployment.yaml) and a way to validate the changes work. It was also a scored service on day 2.
Kubernetes Cluster Upgrade
The inject asked teams to upgrade their Kubernetes cluster to the latest version (1.29). This is pretty simple (Docs) just time-consuming. The one tricky part is replacing the old apt repository (another doc). Upgrading the cluster could be completed with no SLA downtime if teams properly drained and migrated workloads before upgrading the worker nodes.
GitOps Deployment
This inject looked for teams to deploy the application they secured through a GitOps process. The inject email tells them they can copy the setup that was used by the shop application. The first steps would be to create the GitLab project/repo, set up a deploy key or personal SSH key between ArgoCD and GitLab, and then create the application that deploys the K8s manifest.
I also scored this inject, so I’m white team now 🏳️
ETC
If you have more questions feel free to reach out on the unofficial CCDC discord or directly I’m more than happy to answer.
I want to share this year’s video from our teammates colleagues on the red team. Doing great work as always