Annual Northeast CCDC black team competition notes and infrastructure details.
This covers how we set up the environment, qualifier and regional competitions (services and injects) and then some fun stats we collected along the way.
This year Roger Williams University hosted the NECCDC competition. (If you’re not from the NE region, we do things slightly differently. Each year a different host university partners with the League to run the competition)
The theme selected by this years Director at RWU was 3rd Party Risk in the health sector. When deciding how to implement the theme in our infrastructure we dropped the 3rd party risk and let that be covered by injects and for the health sector aspect, we went with a pharmaceutical company that produces & tests placebo pills. We did not pick a traditional hospital setting because most of that type of tech is boring or would step into last year’s theme.
Infrastructure Deployment
How we developed and deployed our infrastructure has not changed much since last year. We are still running the competition on AWS, building with Ansible, and deploying with Terraform.
If you would like to deploy your own NECCDC, we make a public version of our internal repository available on GitHub (neccdc-2025-public). If you have any questions about setup don’t hesitate to contact me.
Qualifiers
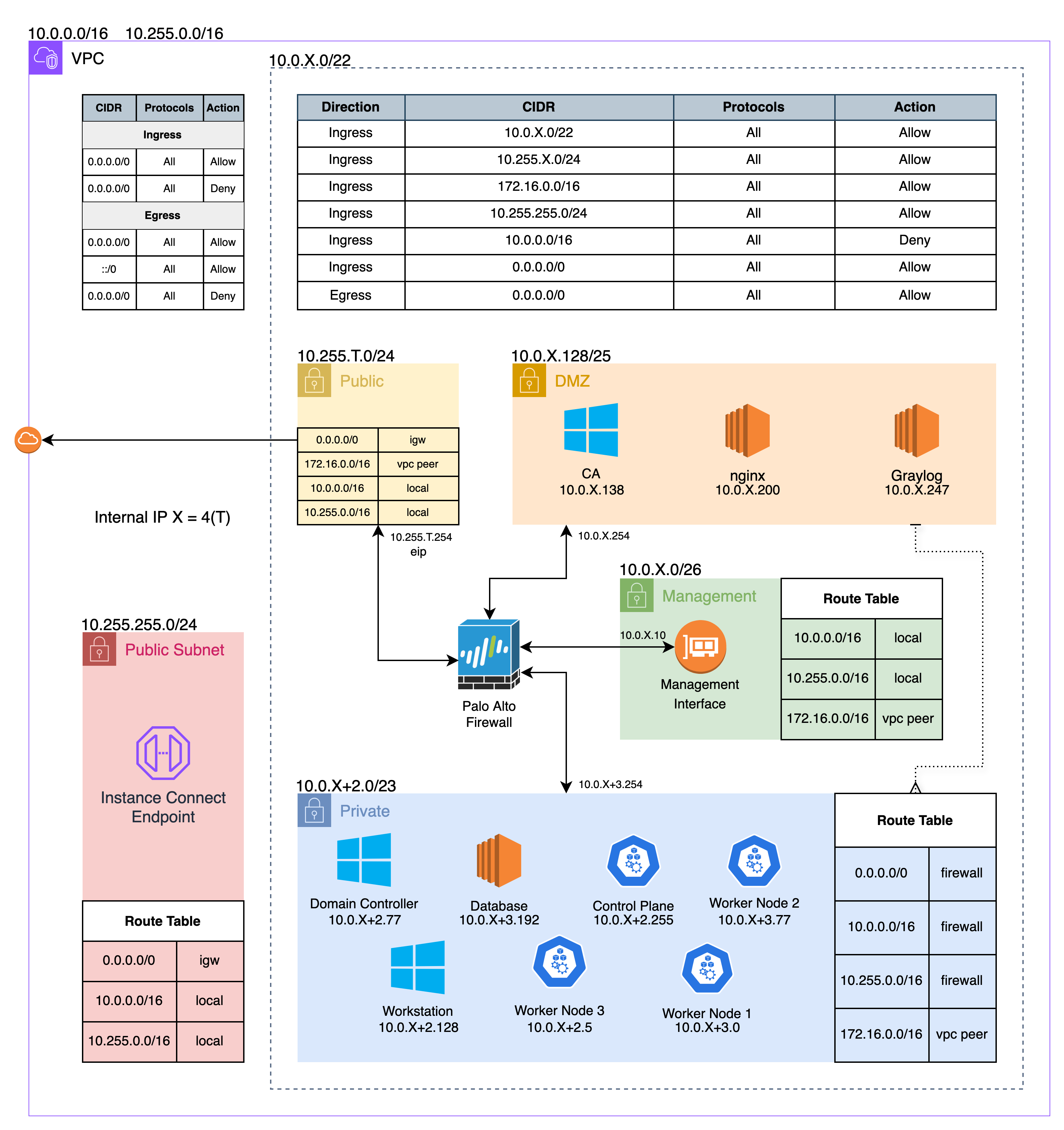
I’m the madman who gave teams the /22, I did not expect teams to have difficulties determining their subnets. Next year I’ll be back…
The Firewall
Teams have been asking for a dedicated firewall ever since 2023 when we gave teams access to the AWS console. So this year we gave it to them, I’ve also been personally wanting to set up the AWS side.
We decided to use Palo Alto because PAN is a national sponsor and we know teams can get training licenses.
To save a little money, we tried to have the firewall fully internal and then egress would go through a NAT Gateway but that did not work so all teams got an EIP attached to their public interface.
The issue
We deploy our infrastructure the night before, primarily to save costs, and because the deployment process is fairly quick. Terraform was applied (8pm) the Palo playbooks were started and completed successfully. However, when we ran any other playbook some of them would fail because they could not connect to the internet. Looking into the teams that had issues we noticed that not all the interfaces on Palo Alto were showing up.
First, we tried redeploying the Palo Alto boxes, but that did not fix the intermittent issue. Also, now is a good time to mention that it takes 10 minutes just to terminate the instance since they do not handle AWS shutdown signals correctly.
At this point (10pm) we found a few posts with people also having the same issue, although for them, it was related to IMDSv1 being disabled. In our case we don’t follow security best practices and have it enabled by default & explicitly setting it on the EC2 instance did not help.
At this point (11pm) we thought it was some issue with the VPC or how we deployed, so we nuked our AWS environment and deployed the Palo Alto code from the previous week we used during the beta test which had no issues.
Now we did not have a proper solution, so we just deployed everything & monitored the CloudWatch Metrics for IMDS connections. For instances that did not make the connection we terminated and redeployed. This worked but for some teams we had to do this several times (20 minutes per redeploy). After we confirmed that all team’s Palo Alto instances were happy, bed (2am) and decided to deploy my instances in the morning and left Andrew to finish the Palo instances.
{kind=link}
{kind=link}
This is why you had pfSense for regionals

Nginx
This server served as a load balancer between the Palo Alto instance and the Kubernetes nodes.
The instance really did not have to do much so we deployed it on an Arm-based instance that was pretty lightweight (t4g.micro). This was fine until teams tried to do anything moderately intensive as this would consume most of the memory causing an OOM crash.
Takeaway from the black team side is we’ll probably start at small instances going forward.
Regionals
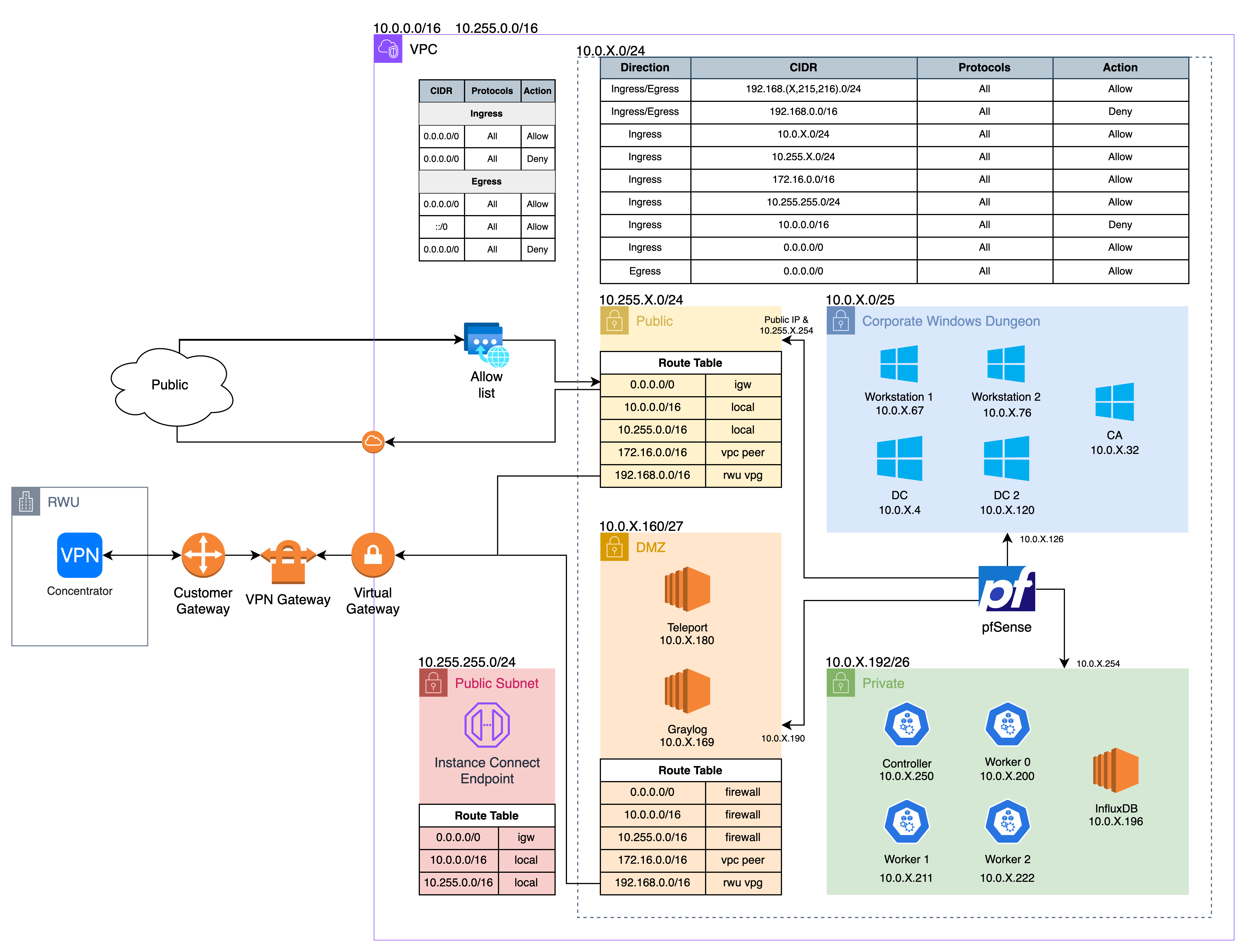
One of this year’s sponsors, OSHEAN, the ISP for RWU was able to set us up with a site-to-site VPN. From our side we set up an IPsec VPN in AWS and they handled the rest. This allowed teams to connect directly to their environments and skip the VPN client setup.
A new feature that was added to our discord bot was the ability for teams to create temporary ticket channels. Blue teams seemed to love it and greatly helped the black team’s ability to track requests. My personal thanks to all teams that performed troubleshooting before opening a ticket. 🫶
pfSense
After the qualifiers firewall issue, we decided not to continue using Palo Alto for regionals. This was chosen as the replacement mainly because we had some setup knowledge. (and not palo)
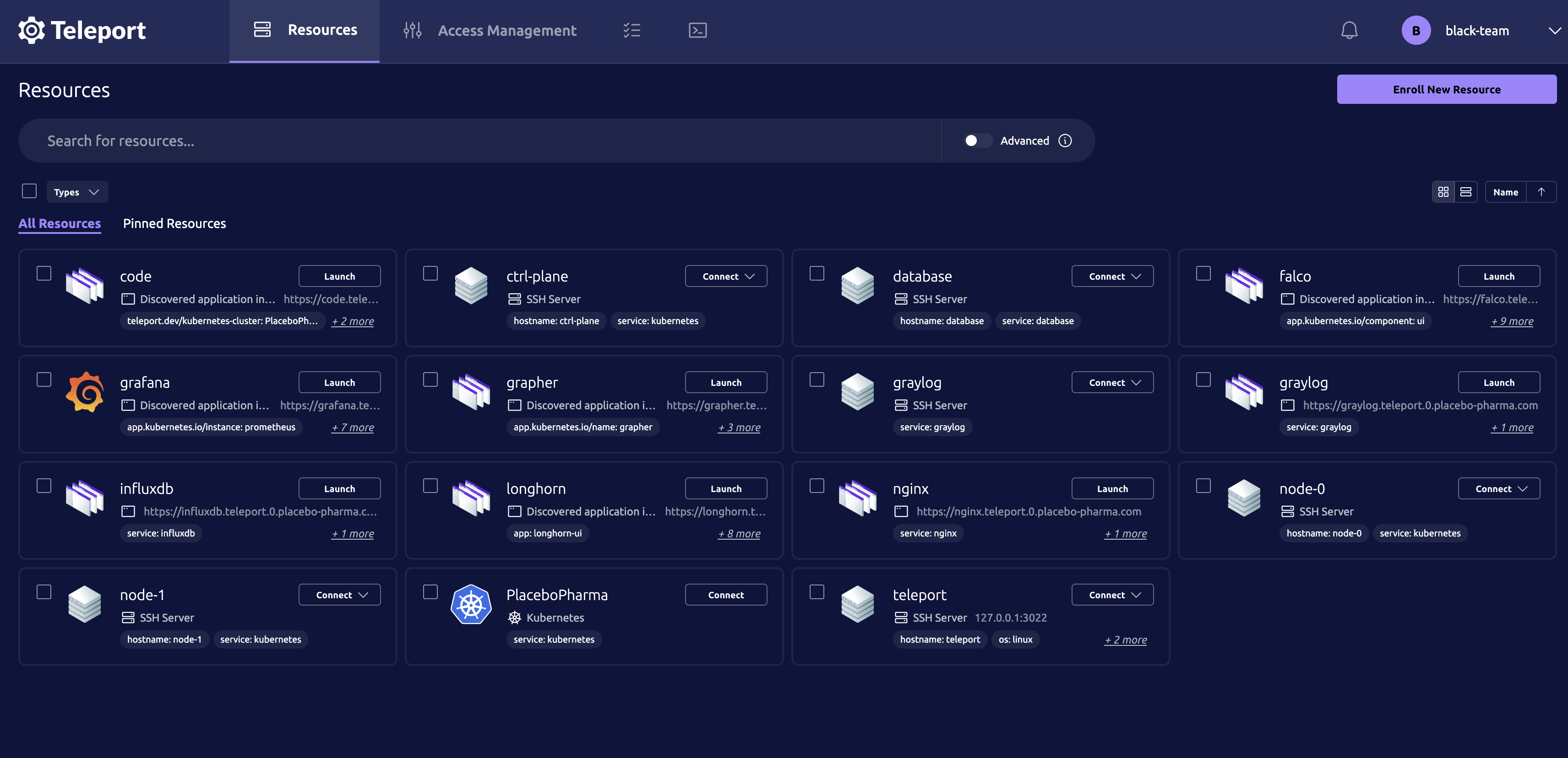
Teleport
Teleport made a comeback, it was originally deployed in the 2023 regionals competition. I was able to improve the Ansible playbook to fully setup the users automatically with a bunch of api requests.
Astute teams may have noticed that we were running Teleport v15 and not the latest (v17). The reason behind this is in version 16 multi-factor authentication is required for all local users.
Kubernetes
The cluster was deployed similarly to last year, deployed with Kubeadm since it deploys a “vanilla” cluster with access to all the control plane components. One thing I did to have some fun was to have each worker node have a different container runtime (cri-o, containerd, docker). I hope you never see a production cluster deployed like this 🤞
We used Calico during qualifiers for our container network interface (CNI). Then Cilium in regionals and had is replace the kube-proxy. (Also layer 7 network policies)
For ingress I wanted to try using the Gateway API. It was deployed with a single gateway class (Traefik) and then exposed using NodePorts which pfSense load balanced. Gateway API is better than using Ingresses but I still prefer what Traefik offers with its CRDs (more control over middleware & tls settings).
Since we were already using Teleport, adding in cluster access was a no-brainer. The Teleport Kubernetes Agent can be easily deployed using Helm and allows accessing internal services directly through the web interface.
Falco
Falco is an amazing tool, if you correctly set up rules and monitor the alerts. It was deployed across all four Kubernetes nodes and used eBPF to capture syscalls and sent warning or higher alerts to teams Discord channel using a webhook. Default and incubating rules were enabled which captures most anomalous activities and we put together a set of rules to suppress the events caused by the normal environment (Longhorn, CRI, Graylog sidecar, etc.)
Fun fact: When using Docker as the CRI it passes the container.image.repository without the docker.io prefix. Now I need two rules for each alert 😕
{kind=link}
Now it’s time to be serious, does this look familiar?
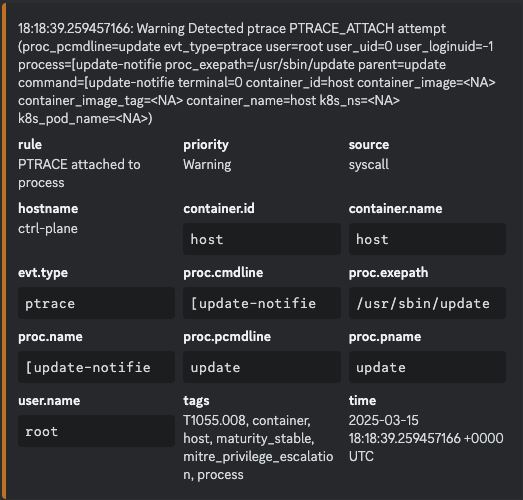
Did your team mute the channel or disable Falcosidekick because of the spam?
On our test team (zero) we got about 2,000 PTRACE attached to process alerts.
I hope next year teams will look into what is actually causing the webhook notifications, because even from my untrained eye I know that does not look right.
The Pipeline
When designing an environment, we want it to feel lively, even if there are no employees actually working at the company. Over winter vacation I put together a basic data pipeline (taking a little inspiration from work)
The high-level concept is that remote plants are pushing data into the environment containing machine analytics and pill trial results.
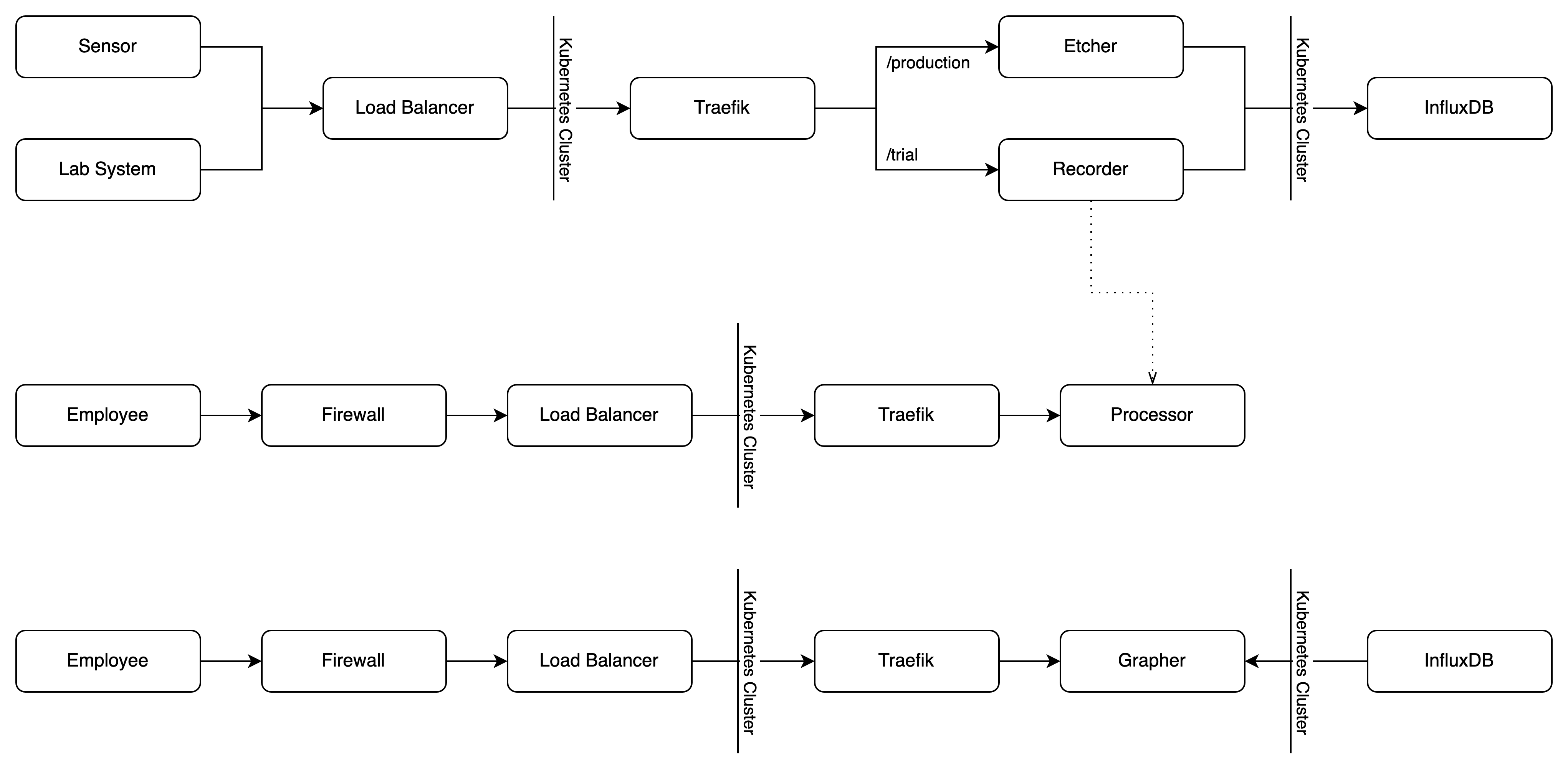
- Etcher: This service accepts http post messages and writes them to InfluxDB to be used by another service
- Recorder: This endpoint receives lab results, writes them to InfluxDB and then triggers a processor job to do “analytics”
- Processor: Processes the results from a lab experiment which takes around 15 minutes. This service was not part of qualifiers
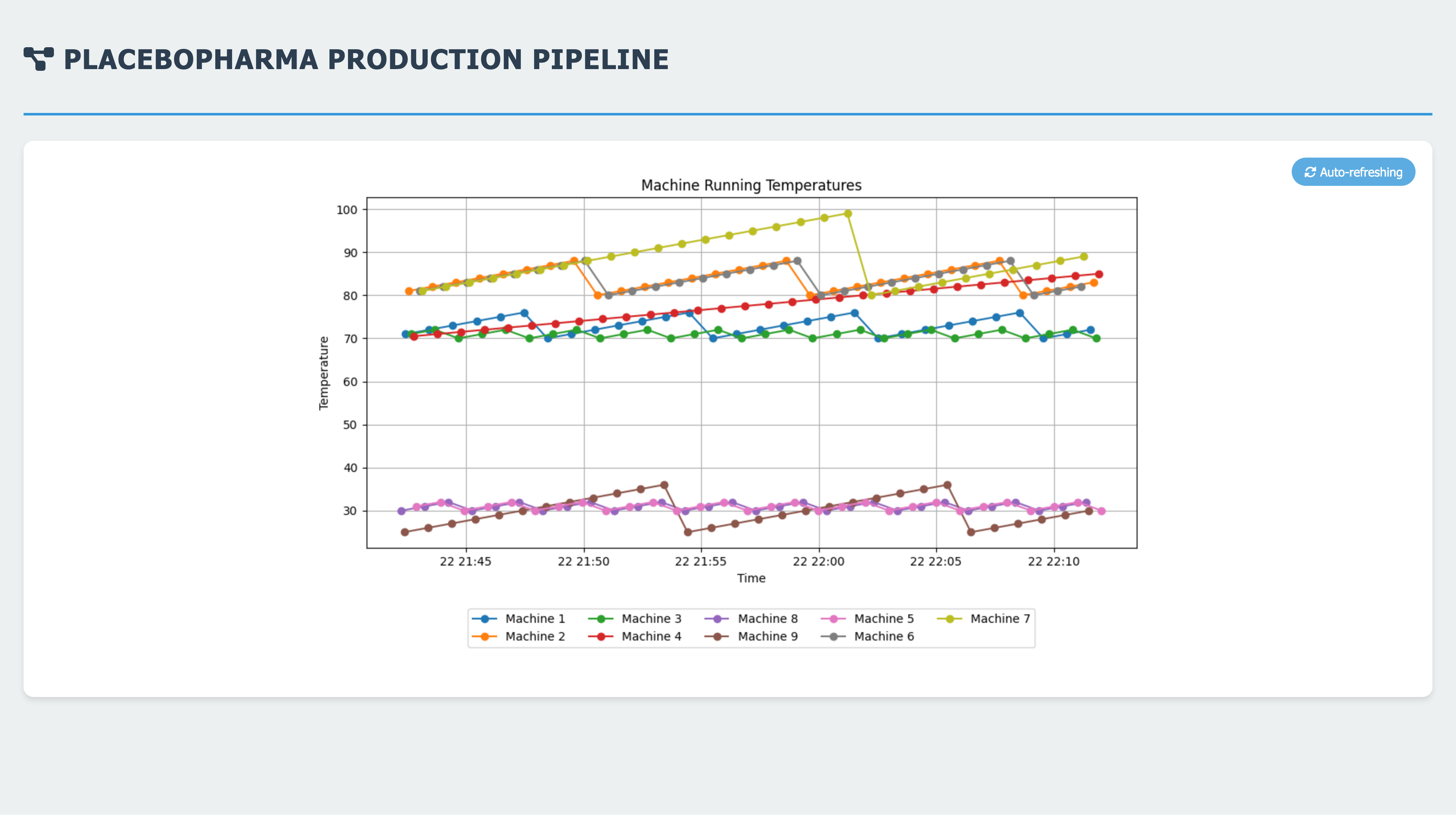
- Grapher: Queries InfluxDB to get the last 30 minutes of machine data and calculates the temperature over time. See the screenshot below
- Pusher: This service runs completely on our side and pushes data into the team’s environments through the firewall. All the data was created by a janky script, written to SQLite and then a docker container pushed the data.
This may seem complicated but this is pretty simple compared to a company that deals with real time data.
Based on feedback from teams it seems like they struggled with Kubernetes this year or just don’t like it 🤷. There were no complex injects like last year and no major red team activity on Kubernetes itself. My personal guess is because the firewall was being hit hard both days which mainly impacted k8s score checks and caused this negative association.
InfluxDB
We knew we wanted a time-series database and selected InfluxDB mainly because it is simple to deploy and administer.
Graylog
We have used Wazuh for the last several years, and we are all still fans of it. But it has been a staple of this competition for too long so we switched it out with Graylog as it supports many of the same features as Wazuh.
Teams did not seem thrilled with the change, not too surprised (change is change). There were two injects related to Graylog, but both were fairly simple so they should not have made a major impact on sentiment.
Our general feedback to teams is to understand the concepts of a SIEM as it’s pretty standardized across different offerings instead of a specific tool.
Injects
When you see double quotes (") it is text directly from the inject body shared with teams.
Stop adding “Thank you” in your executive summaries, you are being asked to do work, not receiving a gift.
Qualifiers
The black team did not supply any injects for qualifiers, but we did assist with the Graylog client installation inject. This inject was pretty straightforward & just required the installation of sidecars on critical servers (DC, ctrl plane, etc.)
Regionals
Regionals is where we stepped up the injects 😈
Outdated K8s Nodes
This was probably the most technical inject we had during the 2025 regionals; it required teams to update their Kubernetes worker nodes to the “latest stable version.” The main challenge with this one is maintaining scored services on Kubernetes while dealing with the relatively short completion deadline. Red team did not impact the success of completing this because this was early on day 1.
Two approaches teams should consider are:
- Allowing the control plane node to schedule pods
- Scaling down non-critical workloads
❯ k get nodes -o wide
NAME STATUS INTERNAL-IP OS-IMAGE CONTAINER-RUNTIME VERSION
ctrl-plane Ready 10.0.0.250 Ubuntu 24.04.1 LTS containerd://1.7.25 v1.32.2
node-0 Ready 10.0.0.200 Ubuntu 24.04.2 LTS cri-o://1.24.6 v1.32.2
node-1 Ready 10.0.0.211 Ubuntu 24.04.2 LTS docker://26.1.3 v1.32.2
node-2 Ready 10.0.0.222 Ubuntu 24.04.2 LTS containerd://1.7.25 v1.32.2-7+dce86010a0fb40-dirty
When grading this inject we noticed most teams did not provide evidence of upgrade or showed package/kubernetes updates. We were looking for explicitly “Kubernetes nodes are running outdated operating systems” being updated to a newer stable Ubuntu version.
Missing Teleport Node
Following the k8s node upgrade we gave a simple inject, we asked teams to enrol a Kubernetes node into Teleport.
This can be easily completed in 2 minutes, from the Teleport console register a new resource (Ubuntu) CTRL+C. Then SSH into the server CTRL+V and you’re done.
Sadly only half of the teams showed proof that they completed the agent installation. ☹️
Risk of 3rd Party Application Containers
This inject was black teams attempt to bridge 3rd party risk into a semi-technical inject. Teams were asked how they can mitigate risks “regarding hosting their [3rd party vendor] SaaS application locally on our Cluster.”
A general theme when reviewing the submissions teams did not identify the risk when running on Kubernetes. Lots of teams identified risks of running 3rd party software but not all of them addressed ways to mitigate them. Data ownership was brought up a bunch as a risk, but this is a feature of self hosting it, as the “primary objective is to maintain control over access to our internal data.”
Here are a few potential solutions to some of the risks with self hosting the 3rd party application on K8s:
- Network policies: Restrict what the 3rd party code can communicate to
- AppArmor or Seccomp: Restrict access to hosts kernel
- gVisor or Kata Containers: virtualize or ‘replace’ the host kernel (sandboxing)
- Dedicated Kubernetes node: complete isolation from other workloads
- Capabilities & user id: Restrict what could be accessed if the container was broken out of
Slides // Presentation
I initially put this together but handed it over to the white teams where they handled the logistics and grading.
Was not able to attend the presentations but from looking through the slides here are a few of my findings:
- The topic did not have to be related to the merger between IllusioPharma and PlaceboPharma
- To many topics, it should “consist of one topic that may have several supporting subtopics”
- It’s not a research proposal and slides should be trimmed down for a presentation
- Not all submissions follow the rules of slideology
Graylog Webhook
This was another straight-forward inject, although many of the teams failed to complete the request.
We were looking for two elements in the implementation:
- Critical alerts were configured in Graylog
- These alerts were sent to Discord over a webhook we provided
There is an official setup guide video directly from Graylog that is only a 3 minute watch.
Graylog Integration
Teams did well on this inject, configuring syslog to be forwarded from pfSense to Graylog and configuring a dashboard to show alerts.
Zero Trust Kubernetes
This inject was not actually written by me or the black team but by someone on the white team. It got approved right away (it mentioned ‘Kubernetes’ /s)
Part of this inject looks for validation of the following controls:
- Network Policies
- Intra-pod communication
- Shell directly on a node
- Kubernetes RBAC capabilities
All four of these can easily be proven or denied, but at this point the red team were freeing up disk space on K8s nodes (rm -rf /etc/kubernetes)
For the second part, we looked for elaboration on zero trust implementation with a service mesh. Most teams scored fine on the (seemed AI written) summary but only a few shined out, showing the pros & cons of implementing a service mesh.
Stats
Regionals had a higher percentage of participants in which was their first CCDC compared to qualifiers. 60% vs 56%
Incorrect spelling of Graylog in feedback forms remained the same at ~15% during qualifiers & regionals. graylog vs greylog
106 tickets were opened during regionals and of them 12 resulted in a service redeployment.
There was a total of 250GB of egress traffic from RWU (blue/red/black/white) and only 16GB over the VPN concentrator.
Stats calculated from the feedback form show teams don’t like new (Graylog, pfSense, Teleport) or complex* (Kubernetes) technology. From my personal experience, teams that are fans of Kubernetes have consistently placed higher. So I think it’s a skill issue
{kind=link}
Misc
Congratulations to our top three teams
I attended UML for a semester in 2021 and am really impressed with how they have improved since then.
Here is your annual red team hacking video
Additional Content
If you enjoy this competition and want to contribute we are always accepting volunteers and new sponsors.
If you have more questions reach out on the unofficial CCDC discord or directly